


Sanitizers are libraries responsible for protecting our applications from Cross Site Scripting (XSS) attacks. They are used when we need to render HTML code stored as a simple string.
Sanitizers receive a string of HTML code as input and parse it, getting rid of unsafe entries that would allow an attacker to inject dangerous JavaScript or CSS code. In theory this sounds effective, but the parsing HTML code is a very difficult issue. Why?
In theory, HTML code is simple: there are nested tags and each of them has different attributes. All we need to do is write a regular expression that splits a code after the “<” and “>” characters and checks all possible places where unsafe code can be injected. However, there are several loopholes here:
- A code doesn’t have to be correct, for example closing tags or attributes may be missing, redundant characters may be added, etc:
1234<div><b onmouseover=alert(‘hello!’)>click me!</div><IMG """><SCRIPT>alert("XSS")</SCRIPT>"\><<SCRIPT>alert("XSS");//\<</SCRIPT><IMG SRC="('XSS')" - Part of the code may be written in an unusual UTF-8 notation:
12<IMG SRC=jAvascript:alert(‘hello!’)><IMG SRC=javascript:alert('XSS')> - JavaScript code might not be simple to mark as unsafe without a deep analysis.
1234<IMG SRC=javascript:alert(String.fromCharCode(88,83,83))><IMG SRC="jav ascript:alert('XSS');"><IMG SRC="javascript:alert('XSS');"> - Some attributes might be unknown for developers who implement a sanitizer:
1<IMG LOWSRC="javascript:alert('XSS')"> - Or a code might be just surprising:
1234<svg/onload=alert('XSS')><LINK REL="stylesheet" HREF="javascript:alert('XSS');"><STYLE>@im\port'\ja\vasc\ript:alert("XSS")';</STYLE><STYLE>li {list-style-image: url("javascript:alert('XSS')");}</STYLE><UL><LI>XSS</br>
For more interesting examples check this: https://cheatsheetseries.owasp.org/cheatsheets/XSS_Filter_Evasion_Cheat_Sheet.html.
How to deal with this?
As you can see, writing a sanitizer is a very difficult task. Especially since browsers are constantly developed, new functionalities are added to them and with them more vulnerabilities. No one can guarantee that the sanitiser result is 100% secure code.
Besides, like any software, sanitizers may contain bugs and for such a crucial task as protecting against the injection of any code into our application, we need a solution that guarantees full security.
So how can we deal with this? What can we do to make sure our code guarantees 100% security? We cannot use solutions that do not guarantee 100% security 🙂
A different approach is needed.Since the parsing problem is very difficult, let’s drop it completely. Instead of rendering HTML from a string, let’s render it from a structure we can safely convert to DOM tree elements. Let’s build a nested structure representing the HTML we want to render.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
type Text = { type: 'text'; text: string; }; type Link = { type: 'link'; href: string; children: Content[]; }; type Paragraph = { type: 'paragraph'; children: Content[]; }; type List = { type: 'list'; children: Content[]; }; type ListItem = { type: 'list-item'; children: Content[]; }; type Content = Paragraph | Link | Text | List | ListItem; contentItems: Content[] = [ { type: 'paragraph', children: [ { type: 'text', text: 'This is a text in a paragraph with some JavaScript code: <script>alert("hello!")</script>.', }, ], }, { type: 'list', children: [ { type: 'list-item', children: [ { type: 'text', text: 'The first element', }, ], }, { type: 'list-item', children: [ { type: 'text', text: 'The second element with a', }, { type: 'link', href: 'https://google.com', children: [ { type: 'text', text: 'link', }, ], }, ], }, ], }, ]; |
And then let’s use ng-template to recursively render the elements:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
<ng-template #textTemplate let-text="text"> {{ text }} </ng-template> <ng-template #childrenTemplate let-children="children"> <ng-container *ngFor="let child of children" [ngTemplateOutlet]="contentTemplate" [ngTemplateOutletContext]="{ content: child }" > </ng-container> </ng-template> <ng-template #paragraphTemplate let-children="children"> <p> <ng-container [ngTemplateOutlet]="childrenTemplate" [ngTemplateOutletContext]="{ children }" > </ng-container> </p> </ng-template> <ng-template #listTemplate let-children="children"> <ul> <ng-container [ngTemplateOutlet]="childrenTemplate" [ngTemplateOutletContext]="{ children }" > </ng-container> </ul> </ng-template> <ng-template #listItemTemplate let-children="children"> <li> <ng-container [ngTemplateOutlet]="childrenTemplate" [ngTemplateOutletContext]="{ children }" > </ng-container> </li> </ng-template> <ng-template #linkTemplate let-href="href" let-children="children"> <a [href]="href" _target="blank"> <ng-container [ngTemplateOutlet]="childrenTemplate" [ngTemplateOutletContext]="{ children }" > </ng-container> </a> </ng-template> <ng-template #contentTemplate let-content="content"> <ng-container [ngSwitch]="content.type"> <ng-container *ngSwitchCase="'paragraph'" [ngTemplateOutlet]="paragraphTemplate" [ngTemplateOutletContext]="{ children: content.children }" ></ng-container> <ng-container *ngSwitchCase="'list'" [ngTemplateOutlet]="listTemplate" [ngTemplateOutletContext]="{ children: content.children }" ></ng-container> <ng-container *ngSwitchCase="'list-item'" [ngTemplateOutlet]="listItemTemplate" [ngTemplateOutletContext]="{ children: content.children }" ></ng-container> <ng-container *ngSwitchCase="'link'" [ngTemplateOutlet]="linkTemplate" [ngTemplateOutletContext]="{ href: content.href, children: content.children }" ></ng-container> <ng-container *ngSwitchCase="'text'" [ngTemplateOutlet]="textTemplate" [ngTemplateOutletContext]="{ text: content.text }" ></ng-container> </ng-container> </ng-template> <ng-container *ngFor="let content of contentItems" [ngTemplateOutlet]="contentTemplate" [ngTemplateOutletContext]="{ content }" > </ng-container> |

Full example: https://stackblitz.com/edit/angular-ivy-iquuzz?file=src/app/app.component.ts.
Real life
The reason we want to use sanitizers is because we let our users use HTML. To use the solution described above we need to convert HTML code that the user has created into our structure. This is very easy to do:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
@Component({ selector: 'my-app', templateUrl: './app.component.html', styleUrls: ['./app.component.css'], }) export class AppComponent implements AfterViewInit { private converter = new Converter([ new TextNodeConverter(), new ParagraphNodeConverter(), new LinkNodeConverter(), new ListNodeConverter(), new ListItemNodeConverter(), ]); @ViewChild('container') container: ElementRef<HTMLElement>; ngAfterViewInit(): void { console.log( this.converter.convertNodes(this.container.nativeElement.childNodes) ); } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
class Converter { private nodeConvertersMap = new Map<string, NodeConverterInterface>(); constructor(nodeConverters: NodeConverterInterface[] = []) { nodeConverters.forEach((nodeConverter) => { this.registerNodeConverter(nodeConverter); }); } registerNodeConverter(nodeConverter: NodeConverterInterface): void { this.nodeConvertersMap.set(nodeConverter.nodeName, nodeConverter); } convertNodes(nodes: NodeListOf<ChildNode>): Content[] { return Array.from(nodes) .map((node) => this.convertNode(node)) .filter((contentObj) => contentObj !== null); } private convertNode(node: Node): Content | null { if (this.nodeConvertersMap.has(node.nodeName)) { return this.nodeConvertersMap .get(node.nodeName) .convert(node, this.convertNodes.bind(this)); } return null; } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
interface NodeConverterInterface { readonly nodeName: string; convert( node: Node, convertChildren: (nodes: NodeListOf<ChildNode>) => Content[] ): Content; } class TextNodeConverter implements NodeConverterInterface { readonly nodeName = '#text'; convert( node: Node, convertChildren: (nodes: NodeListOf<ChildNode>) => Content[] ): Text { return { type: 'text', text: node.textContent, }; } } class LinkNodeConverter implements NodeConverterInterface { readonly nodeName = 'A'; convert( node: Node, convertChildren: (nodes: NodeListOf<ChildNode>) => Content[] ): Link { const hrefAttribute = (node as HTMLAnchorElement).attributes.getNamedItem( 'href' ).textContent; const acceptedProtocols = ['https://', 'http://']; return { type: 'link', href: acceptedProtocols.some( (acceptedProtocol) => hrefAttribute.indexOf(acceptedProtocol) === 0 ) ? hrefAttribute : '', children: convertChildren(node.childNodes), }; } } class ParagraphNodeConverter implements NodeConverterInterface { readonly nodeName = 'P'; convert( node: Node, convertChildren: (nodes: NodeListOf<ChildNode>) => Content[] ): Paragraph { return { type: 'paragraph', children: convertChildren(node.childNodes), }; } } class ListNodeConverter implements NodeConverterInterface { readonly nodeName = 'UL'; convert( node: Node, convertChildren: (nodes: NodeListOf<ChildNode>) => Content[] ): List { return { type: 'list', children: convertChildren(node.childNodes), }; } } class ListItemNodeConverter implements NodeConverterInterface { readonly nodeName = 'LI'; convert( node: Node, convertChildren: (nodes: NodeListOf<ChildNode>) => Content[] ): ListItem { return { type: 'list-item', children: convertChildren(node.childNodes), }; } } |
The code creates a valid, secure structure and checks if the “href” attribute is correct. It’s open to handle new tags.
The full example: https://stackblitz.com/edit/angular-ivy-qtcyzo?file=src/app/app.component.ts.
Popular text editors return similar structures:
- https://editorjs.io/ – An example can be found right on the homepage:

- https://quilljs.com returns structures named Blots (https://github.com/quilljs/parchment#blots):
12345678910111213141516171819202122<!-- Include stylesheet --><linkhref="https://cdn.quilljs.com/1.3.6/quill.snow.css"rel="stylesheet"/><!-- Create the editor container --><div id="editor"><p>Hello World!</p><p>The second line with a <a href="https://google.com">link</a> to Google</p></div><!-- Include the Quill library --><script src="https://cdn.quilljs.com/1.3.6/quill.js"></script><!-- Initialize Quill editor --><script>var quill = new Quill('#editor');console.log(quill.getLines());</script>

- In https://draftjs.org (text editor made by Facebook) developers have access to ContenetState object (https://draftjs.org/docs/api-reference-content-state). It contains a structure of the whole document.
Here’s an example of converting quill.js Blots output to a regular object:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 |
type Text = { type: 'text'; text: string; }; type Link = { type: 'link'; href: string; children: Content[]; }; type Paragraph = { type: 'paragraph'; children: Content[]; }; type Content = Paragraph | Link | Text; interface BlotConverterInterface { readonly nodeName: string; convert( blot: Quill.Blot, convertChildren: (blocks: Quill.LinkedList<Quill.Blot>) => Content[] ): Content; } class TextBlotConverter implements BlotConverterInterface { readonly nodeName = '#text'; convert( blot: Quill.Blot, convertChildren: (blocks: Quill.LinkedList<Quill.Blot>) => Content[] ): Text { return { type: 'text', text: blot.domNode.textContent, }; } } class LinkBlotConverter implements BlotConverterInterface { readonly nodeName = 'A'; convert( blot: Quill.Blot, convertChildren: (blocks: Quill.LinkedList<Quill.Blot>) => Content[] ): Link { const hrefAttribute = ( blot.domNode as HTMLAnchorElement ).attributes.getNamedItem('href').textContent; const acceptedProtocols = ['https://', 'http://']; return { type: 'link', href: acceptedProtocols.some( (acceptedProtocol) => hrefAttribute.indexOf(acceptedProtocol) === 0 ) ? hrefAttribute : '', children: convertChildren(blot.children), }; } } class ParagraphBlotConverter implements BlotConverterInterface { readonly nodeName = 'P'; convert( blot: Quill.Blot, convertChildren: (blocks: Quill.LinkedList<Quill.Blot>) => Content[] ): Paragraph { return { type: 'paragraph', children: convertChildren(blot.children), }; } } class Converter { private blotConvertersMap = new Map<string, BlotConverterInterface>(); constructor(blotConvertersMap: BlotConverterInterface[] = []) { blotConvertersMap.forEach((blotConverter) => { this.registerBlotConverter(blotConverter); }); } registerBlotConverter(nodeConverter: BlotConverterInterface): void { this.blotConvertersMap.set(nodeConverter.nodeName, nodeConverter); } convertBlots(linkedList: Quill.LinkedList<Quill.Blot>): Content[] { let element = linkedList.head; const converted = []; while (element !== null) { converted.push(this.convertBlot(element)); element = element.next; } return converted; } private convertBlot(blot: Quill.Blot): Content | null { const nodeName = blot.domNode.nodeName; if (this.blotConvertersMap.has(nodeName)) { return this.blotConvertersMap .get(nodeName) .convert(blot, this.convertBlots.bind(this)); } return null; } } @Component({ selector: 'my-app', standalone: true, imports: [CommonModule], template: ` <div #editor> <p>Hello World!</p> <p> The second line with a <a href="https://google.com">link</a> to Google </p> </div> `, }) export class App implements AfterViewInit { private converter = new Converter([ new TextBlotConverter(), new ParagraphBlotConverter(), new LinkBlotConverter(), ]); @ViewChild('editor') editor: ElementRef<HTMLDivElement>; ngAfterViewInit(): void { const editor = new Quill(this.editor.nativeElement); console.log(this.converter.convertBlots(editor.scroll.children)); } } |
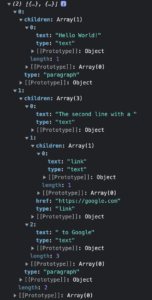
The complete example: https://stackblitz.com/edit/angular-bywfc1?file=src/main.ts.
Benefits
Working on such a structure gives us three huge benefits.
Firstly, we have full control over how the elements will be rendered. We can easily swap a view layer for another. Instead of using standard elements (e.g. links), we can use our own components that add a new functionality (e.g. displays a link with an appropriate icon).
Secondly, content in such a structure can be easily reused in other applications, including those that do not use HTML to render content, for example in mobile applications we can use native mobile components.
Finally, possibilities of XSS attack on this code are much more limited.
As you can see by using this solution instead of HTML with sanitizer we are opening up to the open-close SOLID principle from: our code will be open for extensions and closed for modifications.
For example, we would not have the problem of adding a component that does not exist natively in HTML or changing the display of previously stored content. When storing pure HTML code, we would have to make some tricky modifications to ensure that the user-created HTML code is always processed correctly. When using the structure described in this article, this is very easy to achieve.
Summary
Using sanitizers is a very straightforward and quite common solution to protect against XSS attacks. In this article, I have outlined the risks associated with this. It may be worth investing more time at the beginning of a project in handling a non-HTML structure in order to reap the benefits described above at a later stage.
Leave a Reply