


Angular nabiera impetu, jakiego nigdy wcześniej nie widzieliśmy. We wprowadzeniu do ostatniego artykułu z tej serii zwróciliśmy uwagę, że zarówno w Angularze 14, jak i 15 wprowadzone zostało wiele nowych konceptów i funkcji, przynosząc frameworkowi pewien powiew świeżości. Teraz, patrząc na wersję 16, wyraźnie widać, że tak imponujące tempo rozwoju frameworka stało się standardem. Wierzcie lub nie, ale w NG 16 pojawia się jeszcze więcej przełomowych elementów niż w poprzednich wersjach. Sprawdźmy zatem najważniejsze z nich.
Sygnały w Angular 16
Nie ma wątpliwości, że sygnały to najgorętszy obszar funkcjonalności w najnowszym wydaniu Angulara. Temat sygnałów jest bardzo szeroki i poświęcimy mu wiele treści na naszym blogu. Dlatego nie będę teraz wchodził w szczegóły, ale zamiast tego krótko podsumuję czym są sygnały i dlaczego są tak ważne.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const count = signal(0); const isEven = computed(() => count() % 2 === 0); effect(() => { console.log('Count changed', count()); console.log('Is count even?', isEven()); }); function increment() { count.update(c => c + 1); } function reset() { count.set(0); } |
Koncepcja sygnałów nie jest zupełnie nowa. Niektóre inne frameworki, jak Solid.js, używają ich już od dawna, więc jest to po prostu nowość w świecie Angulara.
Być może słyszeliście już, że sygnały są nowym „reactive primitive” w Angularze i zastanawiasz się, co to właściwie oznacza. O sygnałach można myśleć jako o podstawowej jednostce, na której opiera się system reaktywności. Sygnał jest podobny do standardowej zmiennej w tym sensie, że może przechowywać wartość, do której zawsze można uzyskać dostęp synchronicznie. Jednak poza tym, gdy przechowywana wartość się zmieni, sygnał jest w stanie powiadomić wszystkie jednostki, które od niego zależą. Może to być odczyt sygnału w szablonie komponentu, inny sygnał (computed), specjalna funkcja effect i wiele innych. W ten sposób otrzymujemy wszechstronny element, który jest w stanie powiadomić innych o swoich zmianach wartości, pozwala tworzyć stan pochodny w deklaratywny sposób, a jednocześnie umożliwia synchroniczne odczyty i to wszystko okraszone bardzo dobrą wydajnością. Brzmi zachęcająco?
Dlaczego więc sygnały są tak ważne? Przede wszystkim ze względu na duży wpływ, jaki mogą mieć (i z pewnością będą miały) na inne funkcje frameworka. W tej chwili Angular mocno opiera się na zone.js jeśli chodzi o wykrywanie zmian. Dzięki sygnałom, system reaktywności będzie wyglądał zupełnie inaczej, ponieważ warstwa wykrywania zmian będzie mogła polegać na “powiadomieniach” sygnałów, a następnie wyzwalać re-renderowanie. Tutaj dochodzimy do kolejnego istotnego punktu – technicznie zone.js po prostu informuje framework, że coś mogło się zmienić w modelu danych. Dzięki sygnałom, framework będzie wiedział nie tylko czy coś się naprawdę zmieniło, ale także co dokładnie się zmieniło. Oznacza to, że możemy mieć detekcję zmian per komponent (lub nawet bardziej granularną). To tylko niektóre zagadnienia związane z sygnałami, ale jest wiele innych obszarów, na które mogą mieć wpływ, np. biblioteki zarządzania stanem wykorzystujące sygnały i budujące nowe rozwiązania na ich bazie.
W tym momencie warto zauważyć, że korzystanie z sygnałów jest opcjonalne, więc nadal można używać Angulara zupełnie tak jak wcześniej. Jeśli zastanawiacie się również, czy Angular porzuca RxJS, to zupełnie tak nie jest. RxJS pozostaje obecny i będzie współdziałać z sygnałami.
Jeśli chcielibyście dowiedzieć się więcej o sygnałach, obserwujcie naszego bloga, ponieważ pracujemy już nad pierwszym artykułem na ten temat. W międzyczasie gorąco zachęcamy do zapoznania się z oficjalnym RFC. To właśnie tam zespół Angulara opisał wstępny projekt sygnałów wraz z uzasadnieniem swoich decyzji oraz, co równie ważne, każdy może tam zadawać pytania i dyskutować nad ostatecznymi rozwiązaniami. RFC jest podzielone na cztery części: dlaczego sygnały jako reactive primitive, API sygnałów, komponenty oparte na sygnałach oraz współpraca pomiędzy sygnałami a RxJS. Linki do poszczególnych sekcji znajdują się w głównym dokumencie załączonym powyżej.
Server-side rendering
Renderowanie po stronie serwera to kolejny obszar, w którym dostaliśmy kilka poważnych usprawnień w Angular 16. Do tej pory aplikacje Angular pracujące z SSR korzystały z destructive hydration. Oznacza to, że serwer renderuje aplikację, dostajemy ją na ekranie, a następnie, gdy aplikacja klienta zostanie pobrana i uruchomiona, całkowicie niszczy już stworzone struktury DOM i ponownie renderuje aplikację klienta od zera. Ma to pewne istotne wady, takie jak możliwe mignięcia ekranu czy przesuwanie contentu i negatywnie wpływa na niektóre Core Web Vitals, takie jak LCP lub CLS. Istnieją pewne obejścia, które można zastosować w celu zmniejszenia negatywnych skutków destructive hydration, ale rezultaty są dalekie od ideału i nie rozwiązują sedna problemu.
Angular 16 dodaje wsparcie dla non-destructive hydration. To podejście jest znacznie lepsze: serwer renderuje aplikację, dostajemy ją na ekranie, a następnie, gdy aplikacja klienta zostanie pobrana i uruchomiona, wykorzystuje już istniejący DOM i wzbogaca go o możliwości typowe dla aplikacji klienckiej, takie jak nasłuchiwanie zdarzeń.
Non-destructive hydration jest dostępne jako developer preview, ale można je wypróbować już dziś. Wystarczy dodać provideClientHydration() do tablicy providers podczas bootstrapowania aplikacji standalone:
|
1 2 3 |
bootstrapApplication(AppRootCmp, { providers: [provideClientHydration()] }); |
lub w przypadku aplikacji opartej na module, trzeba dodać tego samego providera do swojego modułu głównego (zwykle AppModule).
Istnieje również możliwość pominięcia hydracji dla niektórych komponentów (a raczej drzew komponentów), jeśli nie są one z nią kompatybilne (np. manipulowanie DOM bezpośrednio za pomocą API przeglądarki). Można użyć:
|
1 |
<test-component ngSkipHydration /> |
lub
|
1 2 3 4 5 |
@Component({ ... host: {ngSkipHydration: 'true'}, }) class TestComponent {} |
Dodano również kilka innych usprawnień dla SSR. Mowa o cache’owaniu zapytań HTTP wykonanych na serwerze w celu ponownego wykorzystania ich w przeglądarce – od teraz implementacja jest częścią samego HttpClienta, a mechanizm ten możemy aktywować za pomocą funkcji withTransferCache. Kolejne to funkcja provideServerRendering, która konfiguruje SSR dla aplikacji standalone (odpowiednik ServerModule).
Required Inputs
Jedną z długo oczekiwanych funkcji jest możliwość oznaczania inputów komponentów jako wymaganych. Do czasu Angular 16 nie było to możliwe, ale istniało częste obejście dla tego problemu przy użyciu selektora komponentu:
|
1 2 3 4 5 6 7 8 |
@Component({ selector: 'app-test-component[title]', // note attribute selector here template: '{{ title }}', }) export class TestComponent { @Input() title!: string; } |
Niestety, takie rozwiązanie jest dalekie od ideału. Pierwszą rzeczą jest to, że zaciemniamy selektor komponentu. Zawsze musimy umieścić wszystkie wymagane nazwy inputów w selektorze, co jest szczególnie problematyczne podczas refaktoryzacji. Powoduje to również nieprawidłowe działanie mechanizmów auto-importu w IDE. A po drugie, gdy zapomnimy podać wartość dla tak oznaczonego inputu, to błąd jest mało dekstryptywny (bo dla takiego „niekompletnego” selektora framework nie znajduje odpowiadającego komponentu):
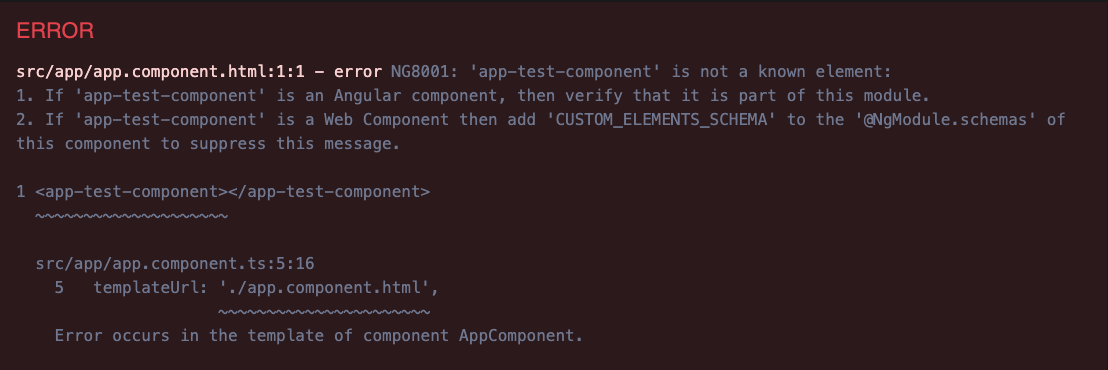
Nowa funkcja wypełnia tę lukę i pozwala nam jawnie oznaczyć inputy jako wymagane, albo w dekoratorze @Input:
|
1 2 |
@Input({required: true}) title!: string; |
lub w tablicy inputs dekoratora @Component:
|
1 2 3 4 5 6 |
@Component({ ... inputs: [ {name: 'title', required: true} ] }) |
Nowe rozwiązanie ma jednak dwie poważne wady. Jedną z nich jest to, że działa tylko w kompilacji AOT, a nie w JIT. Drugą jest to, że nadal kiepsko współpracuje z flagą kompilacji strictPropertyInitialization TypeScript, która jest domyślnie włączona w Angularze (ogólnie jest to zalecane i przydatne). TypeScript zgłosi błąd dla tego pola klasy, ponieważ zostało zadeklarowana jako non-nullable, ale nie zostało zainicjowana w konstruktorze lub w miejscu definicji:
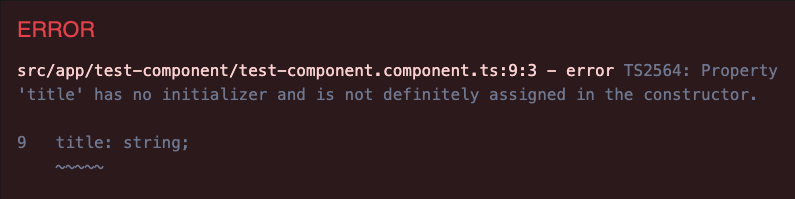
Z tego powodu nadal musimy wyłączać tę weryfikację w tym miejscu np. poprzez jawne oznaczenie tej właściwości za pomocą operatora non-null assertion, nawet jeśli obecnie wartość dla inputa musi być dostarczona w template konsumenta:
|
1 2 |
@Input({required: true}) title!: string; |
Router Inputs
Inną ciekawą zmianą związaną z inputami komponentów jest możliwość wiązania ich bezpośrednio z bieżącymi zmiennymi routera – mogą to być parametry ścieżki, query params itp. Eliminuje to potrzebę wstrzyknięcia ActivatedRoute do komponentu, aby użyć danych routera.
Mówiąc o szczegółach implementacji, dane są wiązane tylko do komponentów “routowalnych” (obecnych w konfiguracji routingu), a inputy komponentów dzieci używanych w szablonach “routowalnych” komponentów nie są dotknięte. Dane routingu są dopasowywane do wejść po nazwie (lub aliasie inputa, jeśli jest obecny), więc może się zdarzyć, że istnieje więcej niż jedno źródło danych, które może być potencjalnie umieszczone jako wartość wejściowa. Poniższa lista pokazuje priorytet powiązania danych z inputami, jeśli ich nazwy są takie same:
- route data pochodzące z resolve
- dane statyczne pochodzące z data
- parametry opcjonalne/”matrix params”
- parametry ścieżki
- query params
Wygląda na to, że jest tu jeszcze więcej opcji, jeśli weźmiemy pod uwagę „dziedziczenie” danych z konfiguracji routingu rodzica, obecności komponentu w tej konfiguracji itp. Można więc przetestować więcej scenariuszy w następującym przykładzie, który dla Was przygotowaliśmy:
esbuild dev server
Wersja 14 Angulara przyniosła oparty na esbuild builder Angulara, ale działa on tylko dla buildów typu produkcyjnego (ng build), a nie dla serwera deweloperskiego (ng serve). W Angular 16 otrzymujemy również wsparcie esbuild dla tego ostatniego. Nowy serwer deweloperski jest oparty na Vite, jednak nadal używa esbuild do budowania artefaktów. Vite działa tylko jako serwer, więc oznacza to, że proces budowania nie wykorzystuje pełnego potencjału Vite. Mimo to jest to spory krok naprzód, ponieważ nadal możemy czerpać korzyści z wydajności esbuilda, a być może w przyszłości będzie więcej integracji z Vite.
Esbuild-based ng build i ng serve oba pozostają eksperymentalne. Jeśli chcecie je wypróbować, po prostu zmieńcie build target dla swojego projektu w angular.json tak, aby używał esbuild (nie trzeba aktualizować niczego w targecie serve):
|
1 2 3 4 |
"build": { "builder": "@angular-devkit/build-angular:browser-esbuild", ... }, |
Inne warte uwagi zmiany w Angularze 16
Jest tak wiele zmian nadchodzących w Angularze 16, że nie sposób opisać ich wszystkich. Ale oto kilka kolejnych, istotnych przykładów:
- Usunięto ngcc (Angular Compatibility Compiler). Biblioteki oparte o View Engine nie będą już działać w projektach Ivy.
- Wprowadzono pojęcie DestroyRef. Jest to injection token związany z cyklem życia komponentu/dyrektywy/injectora. Dzięki niemu możemy zarejestrować callback, który jest wywoływany gdy powiązany element zostanie zniszczony.
12345678@Component({...})class TestComponent {constructor(destroyRef: DestroyRef) {destroyRef.onDestroy(() => { /* some logic */ });}} - operator takeUntilDestroyed został zaimplementowany w samym frameworku. Dzięki temu nie musimy już sięgać po rozwiązania zewnętrzne. Implementacja oparta jest na DestroyRef.
- TypeScript 4.8 nie jest już wspierany, a dostajemy wsparcie TypeScript 5.0. Jest to interesujące, ponieważ wersja 5.0 implementuje dekoratory ECMAScript. W przeszłości dekoratory w Angular polegały na tak zwanych „eksperymentalnych dekoratorach”, które były niestandardową implementacją TypeScript, zanim TC39 zdecydował się na standard dekoratorów. Od teraz w naszych projektach Angular możemy wyłączyć experimentalDecorators, a dekoratory powinny nadal działać, ale będą oparte na standardowej implementacji. Jest tylko jeden wyjątek – dekoratory używane w parametrach konstruktora nie będą działać, ponieważ standard tego nie obsługuje:
1constructor(@Optional() public myService: MyService) {}
Musimy więc zamiast tego użyć funkcji inject:
1myService = inject(MyService, {optional: true}); - Kilka schematics zostało zaktualizowanych, aby wspierać aplikacje standalone: ng-new & application schematic, Angular Universal schematic czy app-shell schematic.
- Bazując na wcześniejszym oparciu Angular Material na MDC w Angular 15, dla wersji 16, zespół pracował nad dostosowaniem design tokenów dostarczonych przez Material Design. Dzięki temu w przyszłości migrować do Angular Material 3 powinna być łatwiejsza i pozwolić projektantom i deweloperom na dostosowywanie UI Angular Material do swoich aplikacji.
Co dalej, po Angular 16?
Biorąc pod uwagę bogaty zestaw funkcji dostarczonych w Angularze 16, możemy spodziewać się, że ten trend będzie kontynuowany. Mówiąc o obszarach, na których będzie skupiał się Angulara 17 i dalsze, są dwa źródła, na których możemy oprzeć nasze przewidywania. Pierwszym z nich pozostaje niezmiennie roadmapa. Drugie to tak naprawdę combo wielu streamów/podcastów z członkami zespołu Angular (jak https://www.youtube.com/watch?v=s9ZFyMkDPmg czy https://www.youtube.com/watch?v=aXfCNbU-9EY). Składając to wszystko razem, możemy spodziewać się dalszego skupienia na developer experience i wydajności, ale również wydaje się, że większość wysiłków będzie skupiona wokół:
- Sygnałów (reaktywność, komponenty oparte na sygnałach, lokalne wykrywanie zmian, podejście zoneless, współpraca pomiędzy RxJS a sygnałami),
- SSR (partial hydration, resumability),
- esbuild builders (brakujące funkcje),
- współpracy z Angular Material wokół wsparcia Material 3.
Podsumowanie
Jak widać, w Angularze dzieje się tak wiele, że momentami ciężko nadążyć za wszystkimi nowymi funkcjami. Na szczęście zespół Angulara dba nie tylko o lepszy developer experience, ale także o kompatybilność wsteczną. Oznacza to, że każdy może przyjąć te zmiany w swoim tempie i pozostaje mieć nadzieję, że ostatecznie wszyscy na nich skorzystamy.
Jakie jest Wasze zdanie? Czy podoba Wam się kierunek i tempo zmian, jakie obrał framework? Będziemy bardzo wdzięczni za Wasze opinie w komentarzach.
Hej!
Wyśmienity artykuł, tylko jak teraz cały koncept Signals będzie się miał do takich bibliotek jak ngrx, ngxs?
Niedawno wdrażałem NGXS do swojego projektu i zapowiada się, że teraz chyba nie do końca będzie potrzbeny.
Jaką praktykę preferujesz?
Pozdrowienia
Cześć Michał, dzięki za komentarz! Jeśli chodzi o połączenie sygnałów i bibliotek do zarządzania stanem, to jest to szeroki temat i ciężko powiedzieć na ten moment w jakim kierunku pójdzie główny nurt. Natomiast te dwa koncepty zupełnie się nie wykluczają, po pierwsze można by poprzestać na używaniu sygnałów wyłącznie na poziomie komponentów do stanu ui/lokalnego, a stan globalny nadal żyłby w storze jak dotychczas. Natomiast zarówno ngrx i ngxs już od jakiegoś czasu eksplorują temat wykorzystania sygnałów w swoich bibliotekach: https://github.com/ngrx/platform/discussions/3796, https://github.com/ngrx/platform/discussions/3843, https://github.com/ngxs/store/discussions/1977. Najnowsza wersja ngrx oferuje już nawet podstawową integrację z sygnałami https://dev.to/ngrx/announcing-ngrx-v16-integration-with-angular-signals-functional-effects-standalone-schematics-and-more-5gk6#ngrx-signals.
Natomiast jeśli chodzi o zupełnie pozbycie się takich bibliotek na rzecz wyłącznie sygnałów, to tracimy wszystkie korzyści reduxa. Wtedy zarządzanie całym stanem jedynie w oparciu o sygnały byłoby zbyt mało skalowalne i wygodne w użyciu (lub wcale nie i wtedy prawdopodobnie nasza aplikacja nigdy reduxa nie potrzebowała).
Pingback: Sygnały w Angularze 16 - Angular.love