


Czym jest Backend for Frontend?
Zacznijmy od krótkiego wstępu czym jest API Gateway. Jest to serwis pośredniczący w komunikacji między klientami, a backendowymi serwisami wystawiającymi API.
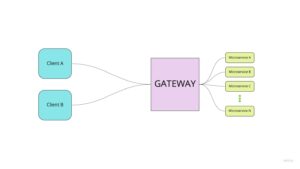
Najważniejsze role i zadania, jakie przy tym pełni to:
-
- bycie pojedynczym punktem styku pomiędzy backendem (który podzielony jest na wiele serwisów), a światem zewnętrznym,
- ukrywanie informacji o podziale backendu na serwisy (z perspektywy klienta backend ukryty za api gatewayem wygląda i zachowuje się jak monolit),
- pełnienie roli reverse-proxy dla backendowych serwisów,
- bycie firewallem,
- możliwość pełnego monitoringu ruchu sieciowego,
- cachowanie, kompresja, load balancing, A/B testy,
- uwierzytelnianie,
- agregacja akcji (wysłanie kilku requestów do różnych mikroserwisów i agregacja odpowiedzi w ramach przetwarzania pojedynczego requesta od klienta).
Ze względu na dwa ostatnie punkty widzimy, że jest to coś więcej, niż tylko proxy. W roli api gatewaya nie występuje po prostu odpowiednio skonfigurowany nginx, lecz pełnoprawny backendowy serwis zawierający w sobie również logikę aplikacyjną.
Backend for frontend jest specyficznym wariantem wzorca api gateway, który wyróżnia się tym, że dla każdego klienta (klient rozumiany tutaj jako osobna aplikacja, np. aplikacja webowa i aplikacja mobilna, lub dwie aplikacje webowe mające różne funkcjonalności) tworzony jest dedykowany gateway (bff).
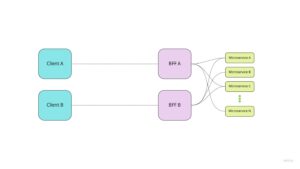
Co to zmienia (względem klasycznego api gatewaya):
- każda para klient-bff może mieć pomiędzy sobą oddzielny, szyty na miarę kontrakt API,
- logika skupiona dotychczas w jednym gatewayu jest rozdzielona na kilka serwisów, zgodnie z jej przeznaczeniem,
- awaria pojedynczego bffa nie odcina od systemu pozostałych klientów.
Backend for Frontend by Frontend
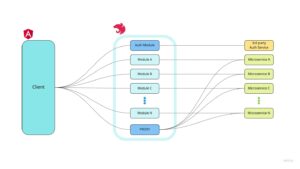
A teraz pójdźmy o krok dalej i przenieśmy odpowiedzialność za stworzenie i utrzymanie własnego bffa do teamu frontendowego (para klient-bff jest nierozłączna, a w przypadku skalowania na wiele klientów podział odpowiedzialności jak na grafice).
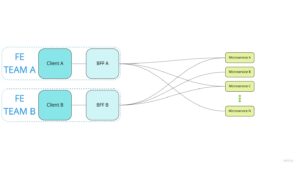
Niesie to ze sobą pewne konsekwencje. Przede wszystkim pole do negocjacji kontraktu pomiędzy frontendem i backendem przesuwa się na kontrakt pomiędzy bffami, a mikroserwisami. Kontrakty i pełna komunikacja pomiędzy klientem i bffem staje się wewnętrzną sprawą teamu FE. Z racji większej odpowiedzialności w teamie FE wymagana jest też obecność co najmniej podstawowej wiedzy na temat tworzenia i działania aplikacji serwerowych. Team FE, kosztem własnych zasobów, ściąga z teamu backendowego część pracy (istotne, gdy w projekcie wąskim gardłem są zasoby ludzkie po stronie backendu).
Jak w pełni wykorzystać bliskość klienta i bffa
Zastosować do tego możemy nasz sprawdzony w boju stack technologiczny:



Gdy mowa o wielu klientach webowych w ramach pojedynczego systemu (np. popularny przypadek aplikacji webowej dla klienta i panelu administracyjnego do zarządzania) świetnym rozwiązaniem staje się monorepo.
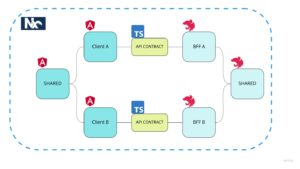
Umieszczając w ramach jednego workspace aplikację webową i bff otrzymujemy między innymi pełne wsparcie typowania typescripta (zapewniające spójność kontraków między nimi). Umieszczając w ramach tego samego workspace wiele par klient-bff otrzymujemy możliwość łatwego współdzielenia reużywalnych modułów.
Implementacja BFF
NestJS, tak jak Angular, opiera się o podział aplikacji na moduły. W naszym przypadku zalecamy podział na moduły odzwierciedlający podział backendu na mikroserwisy (1 nestowy moduł per 1 mikroserwis). Prócz tego w bffie znajdą się też dodatkowe moduły, w szczególności:
- moduł odpowiedzialny za (wstępne) uwierzytelnianie,
- moduł proxy (do prostej obsługi wszystkich żądań, dla które nie ulegają żadnej agregacji po stronie bff).
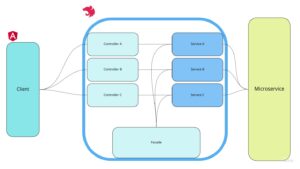
W ramach pojedynczego modułu aplikację podzielić możemy na use-case’y, na które składa się para kontroler-serwis.Pojedynczy use-case obsługuje pojedyncze żądanie przychodzące ze strony klienta. Na potrzeby dalszej agregacji każdy use-case może udostępniać swoją funkcjonalność pozostałym use-case’om (np. poprzez bezpośrednie wstrzykiwanie tego serwisu, lub wprowadzenie dodatkowej fasady).
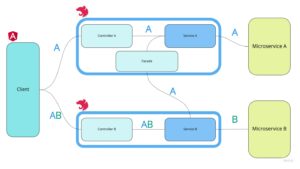
Wspomniana wyżej agregacja polega po prostu na tym, że use-case’owy serwis, prócz wykonania żądania do backendowego mikroserwisu może także skorzystać z funkcjonalności udostępnionych przez inne use-case’y, pobrać za ich pomocą dodatkowe zasoby i skomponować odpowiedź na żądanie klienta (przykład agregacji zasobu A i B do pojedynczej odpowiedzi AB na rysunku poniżej).
Kod każdego use-case’owego serwisu wygląda dość podobnie i składa się z:
- zaimportowania kontraktu API,
- wstrzyknięcia fasad (lub bezpośrednio innych serwisów),
- pobrania głównego zasobu,
- wyłuskania identyfikatorów dodatkowych zasobów,
- pobrania dodatkowych zasobów (w miare możliwości współbieżnie),
- agregacji zasobów w odpowiedź dla klienta (spójnie z kontraktem).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
... // import bff Response type from client-bff API contract import { GetBookDetailsResponse } from '@project-name/shared/contracts'; @Injectable() export class GetBookDetailsQuery { constructor( private readonly httpService: HttpService, // inject facades from other bff modules private readonly mediaFacade: MediaFacade, private readonly userFacade: UserFacade ) { } async handle(bookId: string): Promise<GetBookDetailsResponse> { // fetch basic resource const book = await this.getBookDetails(bookId); // extract ids of additional resources const userId = book.addedByUserId; const mediaId = book.mediaId; // fetch additional resources in parallel using Promise.all const [user, image] = await Promise.all([ this.userFacade.getUserDetails(userId), this.mediaFacade.getMediaDetails(mediaId) ]); // combine all resources into response return this.createResponse({ book, user, image }); } ... } |
Dodatkowe funkcje i antywzorce
Bff może i/lub powinien spełniać następujące funkcje:
- integracja z wybranymi usługami zewnętrznymi (np.autoryzacja, walidacja captchy, logowanie błędów wewnętrznych),
- proxy dla żądań nie wymagających agregacji,
- zmiana sposobu przetrzymywania tokenów autoryzacyjnych (np. jeśli w komunikacji bff – mikroserwis token przekazywany jest w nagłówku żądania to w komunikacji klient-bff skorzystać można z nieco bezpieczniejszych z ciasteczek http-only),
- filtrowanie/forwardowanie błędów z mikroserwisów,
- logowanie żądań/odpowiedzi w ramach komunikacji http z mikroserwisami (pomocne w szczególności w trakcie developmentu),
- cachowanie,
- wersjonowanie kontraktu api klient-bff,
- request-retry,
- SSR (angular universal),
- wszelkie inne tematy związane z security (throttling, CORS, Cross-site request forgery protection, rate limiting itd.),
- system mockowania odpowiedzi dla klienta (z wykorzystaniem bff i kontraktów klient-bff).
Bffowe antywzorce:
- wykonywanie logiki biznesowej (100% logiki biznesowej powinno odbywać się po stronie mikroserwisów, bff to nie mikroserwis!),
- agregacji requestów modyfikujących dane po stronie serwera (ryzyko doprowadzenia do niespójności),
- kilka klientów korzystających z jednego bffa (wtedy mamy doczynienia z klasycznym gatewayem),
- jeden klient korzystający z kilku bffów,
- autoryzacja (weryfikacja dostępu do akcji/zasobu już na poziomie bffa).
Podsumowanie
Nie ma jednego, uniwersalnego rozwiązania w kwestii komunikacji pomiędzy backendem i frontendem. Każde podejście ma swoje wady i zalety. Wzorzec Backend for Frontend (by Frontend) powinien sprawdzić się w szczególności tam, gdzie:
- jest więcej, niż 1 klient dla mikroserwisowych API,
- w zespole projektowym mamy ekstra frontendowe zasoby do utrzymywania dodatkowej aplikacji po stronie FE,
- chcemy uprościć kontrakty opisujące komunikację z mikroserwisami przy jednoczesnym zapewnieniu klientom API szyte na miarę.
Dla frontend developerów jest to też niezła okazja by zdobyć bazowe doświadczenie na temat tworzenia i działania aplikacji serwerowych.
Dodaj komentarz