


Wstęp
To już ostatni artykuł w serii dotyczącej skrótu SOLID. Jest to zbiór zasad, dzięki którym możemy pisać kod, który łatwiej będzie nam skalować, oraz zmieniać zachowanie naszej aplikacji, bez modyfikowania znacznej ilości kodu.
Na zbiór zasad składają się:
- Single Responsibility Principle,
- Open/Closed Principle,
- Liskov Substitution Principle,
- Interface Segregation Principle,
- Dependency Inversion Principle.
Dzisiaj zajmiemy się Dependency Inversion Principle 🙂
Dependency Inversion Principle

https://www.abhishekshukla.com/net-2/dependency-inversion-principle-dip/
Tak jak widzimy na obrazku, korzystając z urządzeń elektrycznych, raczej nie wlutowujemy ich bezpośrednio do instalacji elektrycznej. Zamiast tego po prostu podłączamy urządzenie do gniazdka 🙂
Zatem regułę tę można sobie wyobrazić jako tworzenie “gniazdek” w naszym kodzie, do których będziemy mogli wymiennie podłączać inne urządzenia (serwisy, funkcje itd.).
Formalna definicja
Brzmi ona tak:
- wysokopoziomowe moduły nie powinny zależeć od niskopoziomowych modułów
- oba powinny zależeć od abstrakcji
- abstrakcje nie powinny zawierać szczegółów (bo te powinny być już w konkretnej implementacji)
Co nam daje zachowanie tej reguły?
- łatwo reużywalne, wysokopoziomowe moduły (tzw. building blocks aplikacji)
- zmiany w niskopoziomowych modułach nie powinny wpływać na te wysokopoziomowe. Czyli możliwość zmiany zachowania bez modyfikowania dużej części aplikacji
Tak więc podsumowując:
- wysokopoziomowy moduł musi zależeć od abstrakcji (definiować ją – tworzyć interfejs)
- niskopoziomowy moduł musi też zależeć od tej samej abstrakcji (implementować ją – dostarczać implementację interfejsu)
Przykłady
Najprostszy przykład to Pipe w Angularze. Gdyby nie ten interfejs, nie dałoby się dodawać własnych Pipe’ów do naszych aplikacji (bo wtedy trzeba by było dodawać if’a obsługującego naszego konkretnego pipe’a w kodzie Angulara).
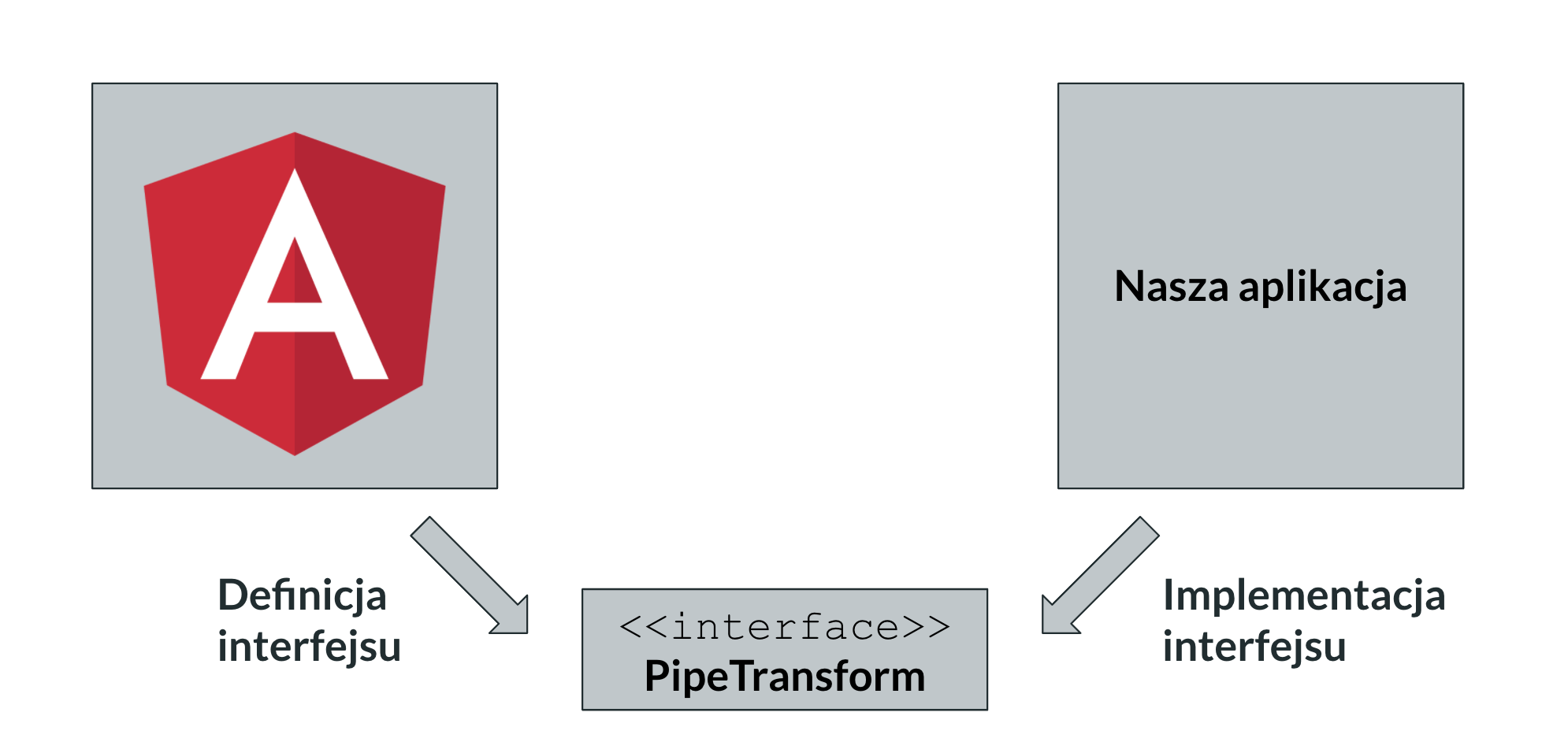
Wysokopoziomowy moduł: Angular – zależy od abstrakcji (definiuje interfejs)
Niskopoziomowy moduł: nasza aplikacja – implementuje abstrakcję (implementuje interfejs)
Kolejny przykład.
Załóżmy że mamy aplikację do zamówień w sklepie internetowym. W związku z tym musimy obliczać podatek w zamówieniu.
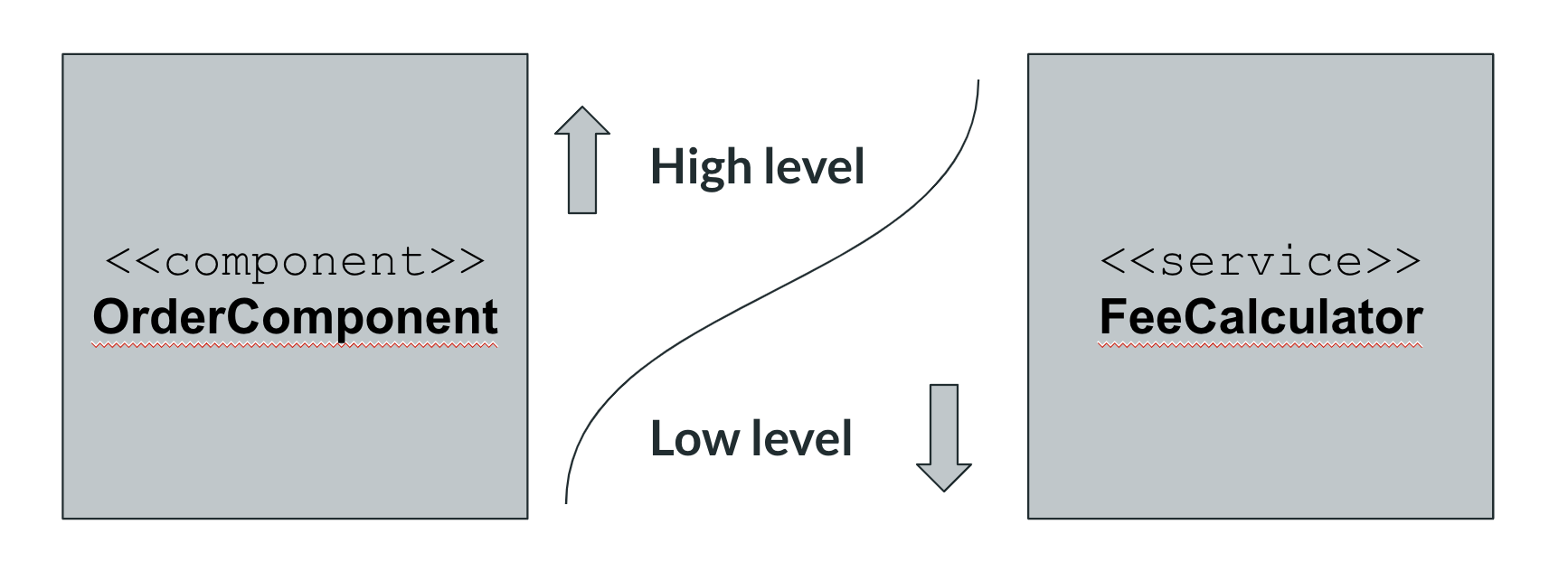
Jako wysokopoziomowy moduł mamy tu komponent ze wstrzykniętym serwisem.
Jako niskopoziomowy moduł mamy serwis.
Dopóki nasza aplikacja działa w obrębie jednego państwa, wszystko jest proste. Jednak co w przypadku, gdy chcielibyśmy wkroczyć na inne rynki? Jak obliczać podatek dla różnych państw?
Naiwne rozwiązanie:
Serwis, który na podstawie przesłanego kodu kraju zwróci odpowiednią wartość:
|
1 2 3 4 5 6 7 8 9 10 11 |
@Injectable() export class FeeCalculator { calculate(code: CountryCode): number { switch (code) { case CountryCode.PL: return 23; case CountryCode.DE: return 21; } } } |
Problem: co jeśli chcemy obsłużyć w naszej aplikacji kolejny kraj? Musimy dopisać “ifa”.
A co jeśli podejdziemy do problemu w sposób bardziej abstrakcyjny? Poszukujemy przecież serwisu, który obliczy podatek dla danego kraju. Wydzielmy więc interfejs, który będziemy implementować w zależności od potrzeby:
|
1 2 3 |
export abstract class FeeCalculator { abstract calculate(): number; } |
PS Jest to wzorzec projektowy strategii 🙂
Po wydzieleniu interfejsu, możemy przejść do implementacji.
|
1 2 3 4 5 6 |
@Injectable() export class PolandFeeCalculator implements FeeCalculator { calculate(): number { return 23; } } |
|
1 2 3 4 5 6 |
@Injectable() export class GermanFeeCalculator implements FeeCalculator { calculate(): number { return 21; } } |
Teraz w komponencie będziemy korzystać z abstrakcji (interfejsu), a nie konkretnej implementacji.
|
1 2 3 4 5 6 7 8 9 10 |
@Component() export class OrderComponent implements OnInit { fee: number; constructor(private feeCalculator: FeeCalculator) {} ngOnInit(): void { this.fee = this.feeCalculator.calculate(); } } |
Spójrzmy, jak możemy teraz dostarczyć odpowiednią implementację na poziomie modułu.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
@NgModule() export class OrderModule { static forPoland(): ModuleWithProviders<OrderModule> { return { ngModule: OrderModule, providers: [ PolandFeeCalculator, { provide: FeeCalculator, useExisting: PolandFeeCalculator, }, ], }; } } |
Ciekawostka:
Co jeśli na poziomie modułu nie wiemy, jakiej implementacji chcemy użyć? Tzn. chcemy dostarczyć implementację “na bieżąco”, w trybie “Live” 🙂
Załóżmy że dostajemy kod kraju jako parametr w URL route’a.
Zdefiniujmy więc fabrykę, która będzie nam dostarczać odpowiednie implementacje na podstawie przesłanego kodu kraju:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@Injectable() export class FeeCalculatorFactory { fromCode(code: CountryCode): FeeCalculator { switch (code) { case CountryCode.PL: return new PolandFeeCalculator(); case CountryCode.DE: return new GermanFeeCalculator(); default: throw new Error('Unknown country') } } } |
Tę fabrykę wstrzykujemy sobie do komponentu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
@Component() export class OrderComponent implements OnInit { fee: number; constructor( private feeCalculatorFactory: FeeCalculatorFactory, private route: ActivatedRouteSnapshot ) {} ngOnInit(): void { const country = this.route.queryParamMap.get('country'); const calculator = this.feeCalculatorFactory.fromCode(country); this.fee = calculator.calculate(); } } |
Przejdźmy do kolejnego przykładu:
Załóżmy, że mamy serwis, który robi CRUD operacje na encji (w postaci requestów HTTP):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
@Injectable() export class FolderDataService { constructor(private http: HttpClient) {} create(data): Observable<void> { return this.http.post<void>('api-url.com/folders', data); } delete(data): Observable<void> { return this.http.delete<void>(`api-url.com/folders/${data.id}`); } update(data): Observable<void> { return this.http.put<void>(`api-url.com/folders/${data.id}`, data); } } |
Co jest nie tak? Na pierwszy rzut oka nic.
Problem pojawia się gdybyśmy chcieli eksperymentalnie wprowadzić obsługę GraphQL na jednym ze środowisk. Wtedy musielibyśmy dodać w każdej metodzie ifa sprawdzającego środowisko:
|
1 2 3 4 5 6 7 8 9 10 11 |
@Injectable() export class FolderDataService { constructor(private graphQl: GraphQLClient, private http: HttpClient) {} create(data): Observable<void> { if (env === 'experimental') { return this.graphQl.execute(...); } // other methods } |
Problem – modyfikujemy istniejący kod, wprowadzając sprawdzanie ifem środowiska. Gdybyśmy chcieli na jeszcze innym środowisku użyć np. WebSocketów, dodalibyśmy kolejnego ifa, i kolejną zależność do serwisu.
Jak to rozwiązać?
Wydzielmy interfejs:
|
1 2 3 4 5 6 7 |
export abstract class FolderResource { abstract create(data): Observable<void>; abstract delete(data): Observable<void>; abstract update(data): Observable<void>; } |
Zmieńmy użycia z konkretnej implementacji na abstrakcję (interfejs).
Dostarczmy konkretną implementację w zależności od środowiska na poziomie modułu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
@NgModule() export class FolderModule { static forExperimental(): ModuleWithProviders<FolderModule> { return { ngModule: FolderModule, providers: [ GraphQlFolderResource, { provide: FolderResource, useExisting: GraphQlFolderResource } ] } } static forStaging(): ModuleWithProviders<FolderModule> { return { ngModule: FolderModule, providers: [ HttpFolderResource, { provide: FolderResource, useExisting: HttpFolderResource } ] } } } |
W ten sposób zachowujemy regułę Dependency Inversion Principle. Przy okazji polecam również artykuł, w którym pokazane jest zachowanie tej reguły przy połączeniu Angulara z NestJS – https://angular.love/2020/12/02/jak-postepowac-zgodnie-z-zasada-odwrocenia-zaleznosci-dip-w-nestjs-i-angular/
Cześć! Dzięki za ten artykuł, bardzo pomocny. Mam jedno pytanie: dwukrotnie w tekście piszesz, że tworzysz interfejs ale w przykładnie podajesz klasę abstrakcyjną. Czy w tym przypadku faktycznie nie lepiej byłoby użyć interfejsu jeśli mamy same metody abstrakcyjne?
Pozdrawiam!