


Wstęp
To już drugi artykuł w serii dotyczącej skrótu SOLID. Jest to zbiór zasad, dzięki którym możemy pisać kod, który łatwiej będzie nam skalować, oraz zmieniać zachowanie naszej aplikacji, bez ruszania kodu dużej części aplikacji.
Na zbiór zasad składają się:
- Single Responsibility Principle,
- Open/Closed Principle,
- Liskov Substitution Principle,
- Interface Segregation Principle,
- Dependency Inversion Principle.
Dzisiaj zajmiemy się Open/Closed Principle 🙂
Open/Closed Principle
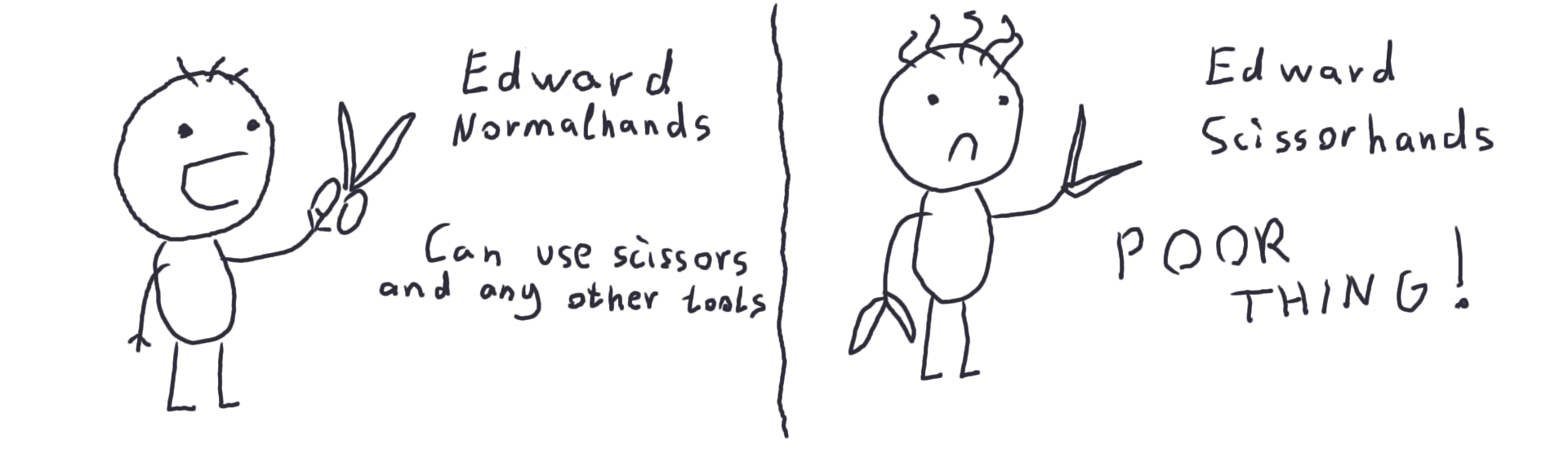
Credit: https://maksimivanov.com/posts/open-closed-principle/
Tak jak widzimy na obrazku powyżej – Edward jest biedny, jeśli ma do dyspozycji tylko i wyłącznie wszyte na stałe nożyczki. O wiele lepiej by było, gdyby mógł korzystać też z innych narzędzi… Tylko jak to zrobić? Może po prostu niech bierze je do rąk, a nie przyszywa na stałe do ciała 🙂
Przechodząc do definicji tej reguły: klasa/obiekt powinien być otwarty na rozbudowę, ale zamknięty na modyfikacje. Co to oznacza? W skrócie – trzeba pisać kod w taki sposób, aby dało się wprowadzać nowe funkcjonalności, bez modyfikowania istniejącego kodu.
Początkowo odnosiło się to do realizacji polimorfizmu (zmieniania zachowania obiektów) za pomocą dziedziczenia. Czyli tworzenia klasy bazowej, i dziedziczenia po niej.
Wtedy:
- klasa bazowa jest zamknięta na modyfikacje ze strony klasy rozszerzającej ją, bo z poziomu klasy rozszerzającej nie mamy wpływu na metody klasy bazowej,
- klasa bazowa jest otwarta na rozbudowę, bo możemy ją rozszerzyć, poprzez dziedziczenie, i rozszerzyć jej funkcjonalność.
Ale dziedziczenie wprowadza ścisłą zależność między obiektami (czyli między klasą bazową, a jej podklasami). Tworząc kod powinniśmy starać się unikać ścisłych zależności.
W przeciwnym razie:
- utrudniamy sobie mockowanie zależności, pisanie testów,
- utrudniamy podmianę implementacji (wymaga to zmiany w wielu klasach),
- tworzymy kod, który jest mniej podatny na zmiany (tworzy się jeden wielki monolit zależności – zmiana jednej rzeczy pociąga za sobą zmianę wielu innych).
Dlatego też zamiast dziedziczenia lepiej używać interfejsów. Dlaczego?
- możemy w łatwy sposób zmieniać poszczególne implementacje (wprowadzając tym samym zmianę zachowania aplikacji), bez zmiany pozostałej części kodu,
- interfejsy są zamknięte na modyfikacje, ale otwarte na rozbudowę (zmieniamy zachowanie, dodając nową implementację istniejącego interfejsu),
- przy użyciu interfejsów nie jesteśmy zależni od implementacji/pól zdefiniowanych w klasie bazowej (jesteśmy więc bardziej niezależni),
- wprowadzamy dodatkową warstwę abstrakcji, która umożliwia “luźne” wiązanie obiektów.
Przykład
Ostatnio zajmowaliśmy się tworzeniem nowej wersji modułu istniejącej aplikacji. Nie chcieliśmy jednak, żeby nowa wersja była widoczna dla każdego użytkownika. Chcieliśmy ograniczyć dostęp do tego nowego modułu tylko do kilku zaufanych klientów. Aby to zrealizować, zdecydowaliśmy się na tzw. mechanizm feature flags.
Działa to w taki sposób, że backend (teoretycznie można by też to zrealizować na frontendzie) zwraca informacje, które funkcjonalności są włączone dla danego użytkownika, a które nie. Jest to odpowiedź, która zawiera wiele pól typu klucz-wartość. Jeśli w którymś z pól otrzymamy wartość „TRUE”, to dana funkcjonalność powinna zostać włączona.
Aby sprawdzić dostęp do nowo utworzonego modułu użyliśmy guarda, który sprawdzał, czy feature flaga pozwala nam dostać się do niego, czy też nie. Dlatego stworzyliśmy taki enum opisujący moduły, i serwis, który posiada metodę do sprawdzenia dostępu do nowego modułu:
|
1 2 3 4 5 6 7 8 9 10 |
export enum AppModule { ORDER, ORDER_NEW, CUSTOMER } @Injectable() export class ModuleAccessService { hasAccessToNewOrderModule(): boolean {} } |
W naszym guardzie wołamy metodę hasAccessToNewOrderModule, i na podstawie jej wyniku umożliwiamy przejście do nowego modułu lub je blokujemy. Na pierwszy rzut oka więc wszystko wydaje się być w porządku – kod działa.
Problem?
Co jeśli będziemy chcieli sprawdzić dostęp do innych modułów? Trzeba byłoby zmodyfikować istniejący serwis, dokładając kolejną metodę do serwisu. W ten sposób nasz plik z tym serwisem mógłby rozrosnąć się do wielu, wielu linii. Oprócz tego, albo guard musiałby znać wszystkie te metody, albo musielibyśmy stworzyć wiele guardów, każdy per moduł, i wiedzieć dodatkowo, jaką metodę wywołać w którym z nich.

Na pewno część z Was spotkała się już w swojej karierze z plikami, które miały setki linii kodu. Jeśli nie, to uwierz mi, nie chciałbyś potem modyfikować czegoś w takim kodzie 😉 Chcielibyśmy uniknąć takiej sytuacji. Dlatego zmodyfikujmy ten kod do lepszej postaci:
|
1 2 3 4 5 6 7 8 9 10 |
export enum AppModule { ORDER, ORDER_NEW, CUSTOMER } @Injectable() export class ModuleAccessService { hasAccessToModule(module: AppModule): boolean {} } |
Teraz gdyby pojawiłby się nowy moduł, do którego chcielibyśmy sprawdzić dostęp, wystarczyłoby dodać linijkę w enumie, i użyć nowej, bardziej generycznej metody serwisu.
To jednak nie byłoby wciąż idealne – nadal musielibyśmy zmodyfikować (prawdopodobnie) wielkiego switcha, który byłby w tej metodzie. Mimo tego, że moglibyśmy mieć już jednego, wspólnego guarda, korzystającego z generycznej metody, to nadal musielibyśmy przekazać do niego odpowiednią wartość enuma.
Zmodyfikujmy ten kod jeszcze dalej. Wydzielmy interfejs:
|
1 2 3 |
export abstract class ModuleAccessService { abstract hasAccess(): boolean; } |
Teraz dla każdego modułu, do którego chcielibyśmy sprawdzić dostęp tworzymy nową implementację:
|
1 2 3 4 5 6 |
@Injectable() export class OrderNewModuleAccessService implements ModuleAccessService { hasAccess(): boolean { // do stuff } } |
Od teraz w naszych guardach korzystamy z abstrakcji (nie z konkretnie stworzonej implementacji):
|
1 2 3 4 5 6 7 8 |
@Injectable() export class OrderNewModuleGuard implements CanActivate { constructor(private accessService: ModuleAccessService) {} canActivate(): boolean { return this.accessService.hasAccess(); } } |
Konkretną implementację dostarczamy np. na poziomie modułu:
|
1 2 3 4 5 6 7 8 9 10 |
@NgModule({ providers: [ { provide: ModuleAccessService, useClass: OrderNewModuleAccessService, }, OrderNewModuleGuard, ] }) export class OrderNewModule {} |
Przy okazji polecam artykuł o tym, jak działa Dependency Injection w Angularze: https://angular.love/2016/12/30/angular-2-injector-tree-jak-dzialaja-serwisy/
W ten sposób trzymamy się Open/Closed Principle. W kolejnej części zajmiemy się Liskov Substitution Principle 🙂
> * klasa bazowa jest zamknięta na modyfikacje…
> * klasa bazowa jest otwarta na rozbudowę…
Czy to aby nie błąd. Czy w drugim podpunkcie nie chodziło o klasę pochodną, która dziedziczy po bazowej?
Konstrukcja tego zdania w poprzedniej wersji artykułu nie do końca jasno to pisała. Zobacz proszę nową wersję, powinno być jasne 😉